




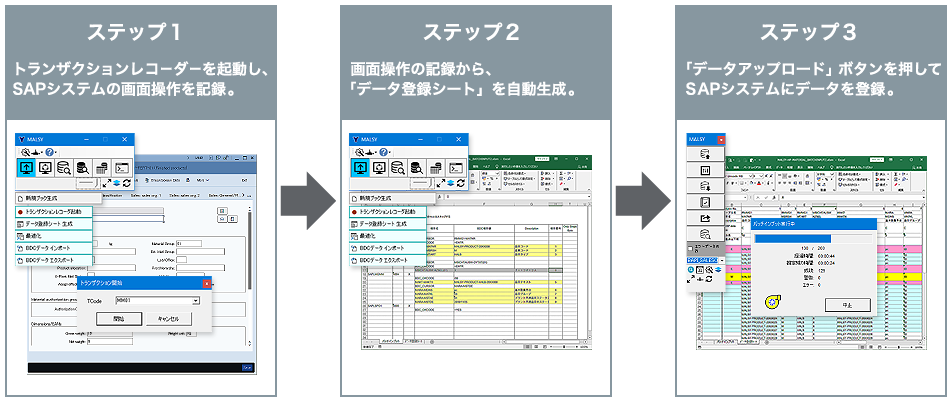









































































































































MapR コンバージド・データ・プラットフォーム
MapRは、オープンソースベースの分散処理ミドルウェアである「Hadoop」を含んだビッグデータ時代のデータ基盤ソフトウェアです。
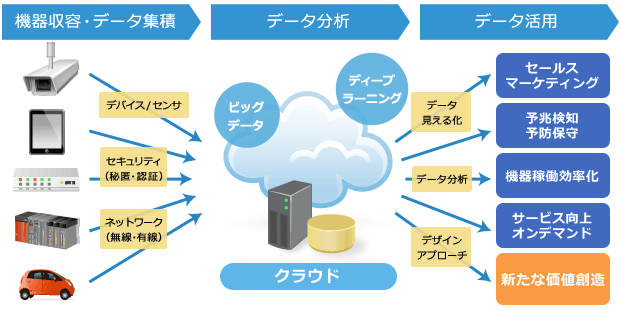
ビッグデータ関連の中でも特にIoTとM2Mの分野において、Hadoop、Spark、NoSQL、Streamingの機能を持ち、バッチ処理もリアルタイム処理も1つのデータ基盤で行えるエンタープライズ向けソリューションとして、ログやデータを活用した障害予兆検知などの幅広い分析基盤を構築します。
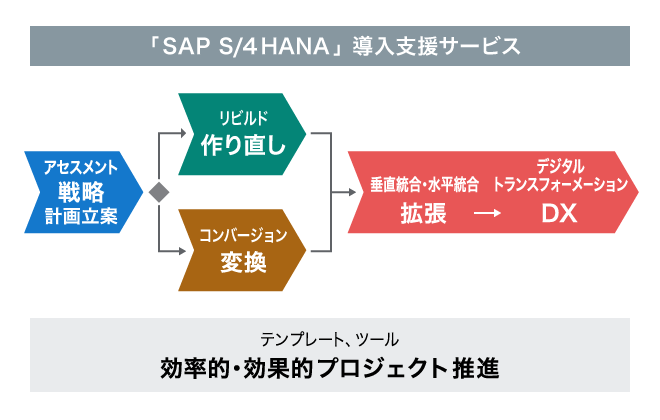
また、クラウドサービス向けには、多目的に供する共通のビッグデータ・プラットフォームとして、高信頼なHadoopクラスタの構築を進め、これらにおいて設計支援/環境構築サービス、データ移行サービスなどサービスメニューを用意し、データ収集から蓄積、活用までのシステムをワンストップで提供します。

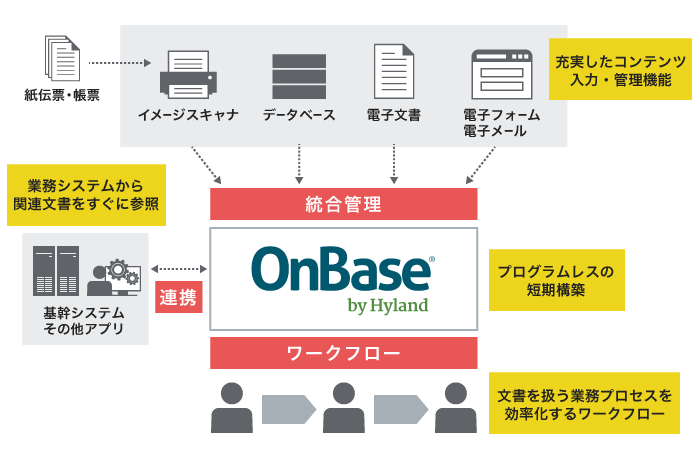
MapRの特長
エンタープライズ向けに機能を強化
MapRでは、Hadoopの分散処理を実現するためのファイルシステムである「HDFS」を独自のファイルシステムにすることで、ボトルネックや単一障害点の解消と機能強化を図っています。

ハードウェアの限界性能を引き出すために、ファイルシステムのアーキテクチャを再設計・再実装しています。
- 強力で柔軟な独自HDFS互換ファイルシステムに各種分析に必要な機能を搭載
- ビルトイン圧縮によるI/O削減
- 分散NameNode
- RPC経由のShuffle転送
- ファイルシステムのネイティブ化によるJava GCの影響やオーバーヘッドの排除
- インターフェースは標準準拠
外部システムとの接続が容易
MapRのファイルシステムは、NFS(Network File System)としてマウントできるため、Hadoop以外のシステムからも市販のNAS(Network Attached Storage)と同様に入出力が可能です。これはNFSストレージとしても利用可能です。

パフォーマンスと信頼性を向上
Hadoopでは1つのクラスタに1つのNameNodeで管理されていたメタデータを、クラスタ全体に分散して管理することで耐障害性とスケーラビリティを向上しています。

パッケージ・エコシステム
MapRは、HadoopやOSSのエコシステムとの互換性を検証した上で製品パッケージとして提供されています。

MapRは、MapR Technologies社![]() の製品です。
の製品です。
