会議のモノラル音声を話者ごとに分離!
音声分離サービス waketekoo
話者の音声分離で議事録の精度を一段上へ!
waketekooは被った音声を分離。
議事録作成や会議・通話録音文字起こしの精度を高めます。
※試使用版を希望の方はお問い合わせ内容欄に「試使用申込」とご記載ください
こんな経験はありませんか?
・録音を確認しても、誰が何を話していたのかが分からない
・同時に発話した音声では、テキスト化が困難
・録音しても、データの利活用ができない

従来の録音機能を利用した音声データのテキスト化では、録音した音声を文字起こししても、「誰が何を話したのか判別できない」「同時に発話した区間の音声では文字起こしがうまくいかず、テキストが読めない」「手間をかけてデータにしても、精度が悪くデータの利活用が進まない」という課題がありました。
waketekooを利用すれば!
◎コンプライアンスの徹底を図れます
◎議事録の作成、自動要約に活用できます
◎対面応対などの録音で、応対品質を評価できます
音声分離サービス waketekooは重なった音声も適切に分離し、文字起こしなどの後工程をスムーズにします。
これにより議事録作成や自動要約、応対品質評価など、多様なデータ活用が可能になります。

\ サービス紹介資料はこちらから /
※料金体系についてはフォームのご連絡事項欄に価格表希望の旨をご記載ください。
※同業他社からのお申し込みはお断りさせていただく可能性がございます。
サービスの特長
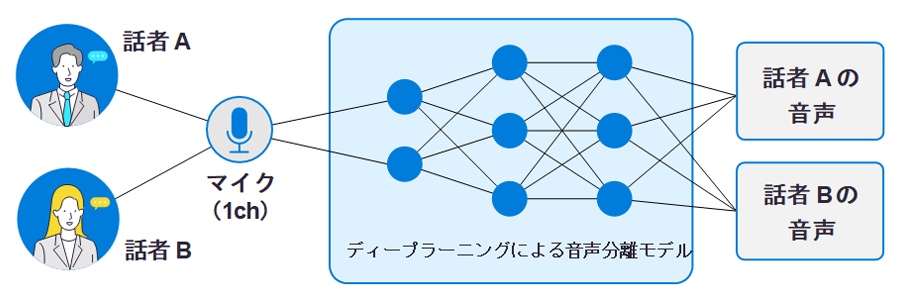
1.複数話者の音声を分離し文字起こしをスムーズに
- 複数話者が同時に発話している音声を分離することで、音声データの文字起こしの精度を高めます。
- 性別や言語に関係なく、会話を分けて記録できます。
- 会議や通話の参加人数に制限はなく、同時に話した場合も2人までなら分けて処理できます。
- 三菱電機のAI技術Maisart®※1を活用して開発された音声分離技術を使用しています
※1 Mitsubishi Electric's AI creates the State-of-the-ART in technologyの略。全ての機器をより賢くすることを目指した三菱電機のAI技術ブランド。
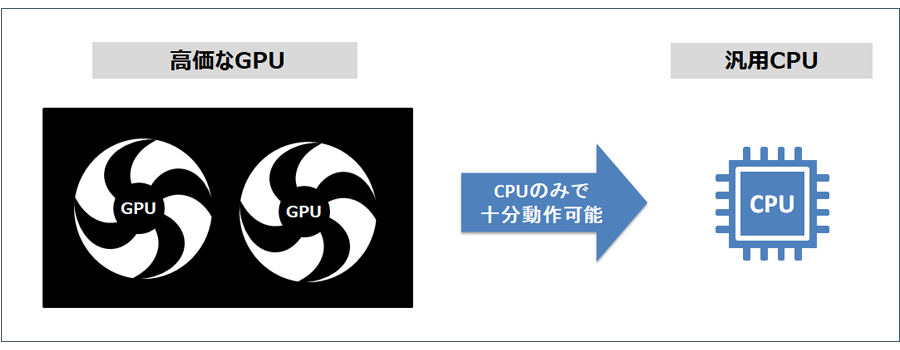
2.導入のハードルが低いシステム要件、価格設定で提供
- AIで一般的に使用される高性能GPU(画像処理プロセッサー)を使わないシステム構成が可能です
3.導入要件に応じ選択できる3つの提供パターンを用意
- Webブラウザから音声分離・話者分離・文字起こしが利用可能な「SaaS型」※2
- お客様の環境構築不要でAPIを通じて利用可能な「クラウドAPI型」※2
- オンプレミスやクラウド環境などで柔軟に利用可能な「モジュール提供型」
※2 サービス基盤としてアマゾン ウェブ サービス(AWS)を利用しています。
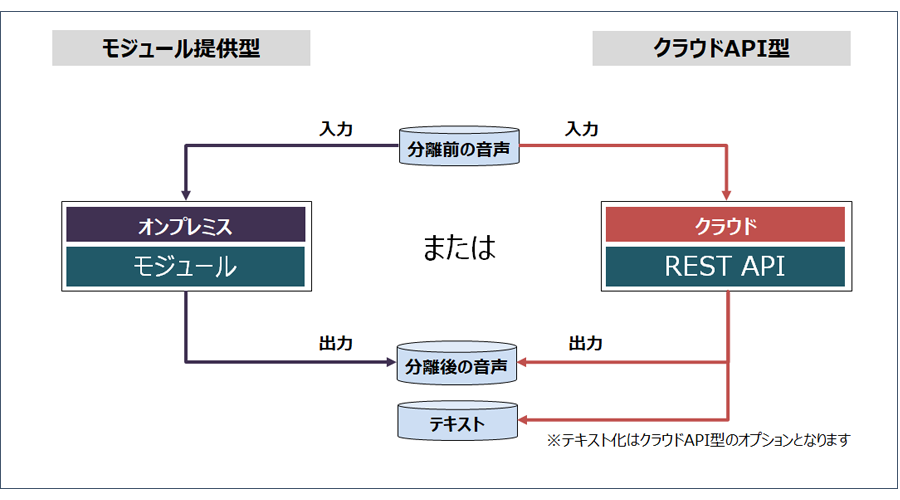
Webブラウザから音声分離・話者分離・文字起こしが利用可能です。
お客様の環境構築不要でAPIを通じて利用可能です。
オンプレミスやクラウド環境などで柔軟に利用可能です。
お困りごとがありましたら、まずはお気軽にご相談ください!
\ サービス紹介資料はこちらから /
※料金体系についてはフォームのご連絡事項欄に価格表希望の旨をご記載ください。
※同業他社からのお申し込みはお断りさせていただく可能性がございます。
